

High search ranking no longer guarantees a sale. AI recommendation layers, shopping graphs, and conversational assistants now make the call about which products get discovered and purchased.
The structural claim of this essay is simple: ranking opens the door; machine-legible product signals and off-site citation velocity decide whether a prospect walks through it and buys.
Similarweb found AI-driven referral visits tripled year-over-year while Ahrefs and Semrush documented steep CTR declines after AI Overviews began surfacing answers directly in results.
This piece proceeds as a practical proof. First, I establish the paradox: high rank does not equal purchase. Next I show the hidden variable operators must manage: machine-legible product data and feed freshness. Then I treat recommendation engines as the decision layer, explain conversational shopping rules, distinguish answer-engine optimization from legacy local SEO, and end with the operational reframe every ecommerce team must adopt this quarter.
1. High Google Rankings Still Matter, but They Stop Short of Deciding Purchases
The opening provocation is not a prediction about search volume. It is a claim about conversion mechanics: high rank still matters because it remains the gating mechanism for inclusion, but rank no longer determines purchase outcomes because generative layers and recommendation modules intercept intent before a click can translate into a sale.
For several years operators have treated organic CTR as the proxy for discoverability. That proxy now breaks when search interfaces answer queries inside the experience. The result is an odd combination: impressions rise while outbound clicks fall. Third-party analytics firms repeatedly documented this pattern in 2024 and 2025, and the industry settled on a diagnosis: the summary layer answers many commercial questions directly. The implication is that a top-ranked page can be visible but invisible as a sales opportunity because the interface has already converted the user's intent into an internal recommendation or a summary that names a different product.
AI Overviews absorb commercial intent before a prospect clicks
Generative summaries do more than restate facts. They convert an ambiguous query into an internal decision signal for the interface. A shopping question that once required scrolling, comparison, and a click is now often resolved inside an AI Overview or an assistant reply. When an LLM or a search-mode model synthesizes product attributes, it implicitly ranks the available options and surfaces the ones that best match the inferred buyer preference. This internal decision reduces the utility of CTR as a measure of visibility because users receive actionable recommendations inside the UI. The phenomenon is visible across industry analyses: there is a measurable decline in outbound CTR once AI summaries are present even when impressions do not decline.
The failure mode here is instructive. If teams optimize exclusively for organic position signals and on-page copy, they will miss the upstream decision the model makes. A page that wins a classic ranking slot but lacks canonical, machine-readable attributes is unlikely to be favored by the generative layer that aggregates evidence and issues a recommendation.
Search rank is necessary but not sufficient
Search rank still functions as a gate. Without rank, a product will rarely be considered by downstream modules. But rank becomes a prerequisite rather than the outcome: it opens the set of candidate pages an AI or recommender can cite. The recommender then applies different criteria: normalized attributes, freshness, citation trust, and behavioral similarity. The practical consequence is that teams must manage two separable problems. The first is how to appear in indexable results; the second — and newly decisive — is how to appear in the evidence set that generative models and recommendation systems consult when they transform exposure into a purchase suggestion.
Google Search Central has updated guidance to reflect this shift by asking creators to prioritize content that performs in AI-driven experiences rather than only in classic SERPs. The shift means that an SEO win alone no longer guarantees commercial return; operators must follow the evidence the models use to form their answers.
2. The Hidden Variable Is Machine-Legible Product Data, Not Page-Level Keywords
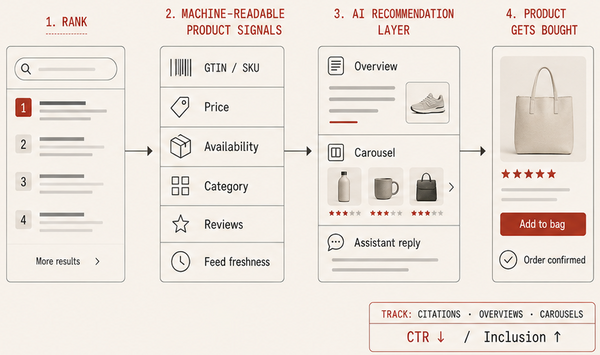
The decisive variable for inclusion in AI Overviews, shopping graphs, and recommendation carousels is not elegant on-page copy but clean, normalized, machine-readable product data. When recommendation layers assemble candidates they prefer structured fields they can parse deterministically: title, brand, standardized category taxonomy, GTIN or SKU, price, availability, color and size enumerations, and shipping expectations. That preference turns product feed engineering into the operable SEO for AI-first discovery.
Google's Shopping Graph and other merchant indexes now operate at scale and at cadence. These graphs index tens of billions of listings and refresh frequently, which means stale feeds or inconsistent attributes create exclusion risk. The consequence is practical and binary: if your feed is not machine-readable, you will be omitted from the set of candidates the AI can meaningfully compare.
If your feed is not machine-readable, you will be omitted
Recommendation systems and shopping graphs do not read aesthetic prose. They read attributes. Missing or inconsistent SKU IDs, malformed price fields, or ambiguous availability flags create parsing failures or lower confidence scores for your items. The downstream recommender treats those items as lower-quality evidence and will prefer products with cleaner, more complete records.
Operators should verify a minimum viable attribute set exists for every SKU. That verification means ensuring canonical identifiers (UPC, GTIN), normalized category labels, deterministic price and inventory fields, and customer-facing microcopy mapped to short summary fields that feed APIs and schema. Merchants that expose these attributes in feeds, in structured data on product pages, and in platform APIs increase the chance their products are included when internal decision layers synthesize an answer.
There is one clear failure case. Shops that depend on handcrafted page copy and long-tail keyword mining but treat feeds as an afterthought will find their pages ranking and yet never cited inside Overviews or assistant replies. The on-page win fails to become a commercial win because the model cannot trust the site as a source of machine-legible product evidence.
Refresh cadence beats tiny SEO tweaks
The second practical truth is that temporal accuracy matters more than micro-optimizations to copy. Recommendation and shopping graphs prefer records that reflect near-real-time price and inventory. A product listed as in-stock yesterday but out-of-stock now will be downgraded by live modules that reconcile availability and price across sources. That downgrading elevates the feed refresh cadence from an operational cost into the chief lever of discoverability.
Feed engineering disciplines therefore become acquisition work. Teams that increase feed freshness, maintain accurate pricing signals, and map availability to standardized enums will appear more often in live recommendations. Incremental headline tweaks that improve human click propensity do not move the needle against a system that privileges accurate, current, and machine-readable truth.
3. Recommendation Engines Are the Decision Layer. They Turn Exposure into Purchase Outcomes

Recommendation systems, not position on a results page, now do the heavy lifting of turning visibility into revenue. These systems apply embeddings, vector similarity, and behavioral signals to project user intent and surface candidates that maximize conversion probability. The system-level effect reproduces what operators have seen inside large marketplaces: small relevance advantages compound into dominant share within carousel placements and assistant prompts.
McKinsey's research on personalization underlines how revenue lifts accrue when recommendations match user context and behavior. The implication is operational: to win the recommendation layer you must optimize the signals the engine consumes, not the human-visible ranking signal alone.
Embeddings privilege behavioral similarity over keyword matches
Modern recommenders convert product and user data into vectors. Those vectors capture behaviorally relevant features such as purchase sequences, co-purchase patterns, historical conversion rates for similar queries, and price sensitivity. The vector space rewards products that sit near historically successful purchase patterns for the given context.
The practical change this creates is subtle but consequential. Where classic SEO rewarded lexical matching and topical authority, vectorized systems reward semantic and behavioral proximity. As a result, merchants with products that align with typical buyer journeys will enjoy outsized exposure in recommendation placements even if their pages do not rank first for a keyword. Conversely, perfectly optimized product pages that lack behavioral signals will be invisible inside recommendation carousels.
Amazon's long-documented recommender mechanics are the clearest proof point for this logic. Amazon routes buyers to products through behavioral similarity and contextual placement; that routing is why recommendation-driven revenue persists even as organic search dynamics evolve.
Placement and format create winner-take-most dynamics
The format of a recommendation — carousel, assistant suggestion, chat-based shortlist — determines conversion leverage. Carousels that appear at the top of a shopping view or an assistant that provides a single recommended product create winner-take-most outcomes where a small relevance edge turns into outsized sales. The consequence for operators is behavioral: optimize for the formats likely to drive transactions, and accept that small improvements in relevance engineering can scale disproportionately.
This leads to a measurable complication. When platforms expose checkout inside the assistant or the recommendation module, the path from exposure to purchase shrinks. That shrinkage amplifies the effect of placement because friction falls and the model's initial ranking has the last clear chance to influence behavior. As a result, teams must invest in product-level signals and in placement-specific testing rather than assuming that a top-SERP position will convert as it once did.
4. Conversational LLM Shopping Rewards Attribute-First, Citation-Ready Copy
Conversational shopping interfaces are increasingly endpoints for purchase, not just research tools. OpenAI's work to enable shopping features and instant checkout inside ChatGPT is a clear signal that chat-first models expect compact, attribute-first summaries and canonical links they can cite when they recommend products. The writing style that wins conversational citations is different from the long-form SEO copywriters have optimized for over the last decade.
Concise, attribute-first summaries get cited
When an LLM generates a shopping reply it has to compress product information into an answer the user can act on. Models show a strong preference for short, structured descriptions that present price, stock status, and core differentiators. A canonical link improves the likelihood a model will name and cite the source, because the model uses the link as an external pointer to evidence.
Operators should therefore assemble canonical, machine-friendly summaries for their best products. These summaries should be accessible to conversational endpoints either via structured schema on the page, a merchant API, or an up-to-date product feed. The goal is to reduce the friction between an assistant's understanding of the product and the user's opportunity to purchase.
There is a practical test to validate whether your copy works for conversational models. Teams should sample responses from multiple LLM endpoints using buyer prompts and evaluate which formats the models cite. This experimentation determines whether the model prefers bulleted specs, short narrative, or a single-line price-plus-differentiator format when producing a recommendation.
Test across models, not just search consoles
Not all models behave the same. ChatGPT, Perplexity, and Google's AI Mode produce different citation behavior and different tolerance for length and detail. Running a simple A/B across models reveals the formats they prefer and the citation cues they use. Operators who assume a win inside one model will generalize across the ecosystem at their peril. The practical fix is systematic sampling: run the same buyer prompt across three or four models, archive the results, and normalize the winning summary format into a canonical product summary stored in your product feed or merchant API.
5. Answer Engines and Local Generative Modules Reward Structured Signals, Not Classic SERP Tactics
Local and answer-engine optimization is a different discipline from traditional local SEO. The win condition is inclusion in generative summaries and local recommendation modules, not higher positions on a ranking list. These generative modules rely on structured local signals: verified address, hours, inventory, reservation and pickup availability, and review metadata. Exposing these signals in machine-readable form is the path to being recommended in a local generative module.
Local signals must be machine-first, not just human-friendly
Local generative modules consult structured store data to decide which merchant to recommend. Human-facing welcome copy and optimized landing-page headings matter less to these systems than the presence of consistent machine-readable store records across directories, platform APIs, and your own site. That means merchants should prioritize accurate hours, canonical NAP records, inventory flags, and schema markup that expresses the same truth the platforms expect.
The complication is that local modules sometimes conflate historic prominence with current relevance. A store that has many directory references but inconsistent current inventory will still be cited less often than a smaller store with reliable, structured signals. The operational implication is clear: clean, current structured local signals beat legacy attention in generative modules.
AEO is about inclusion in summaries, not classic rankings
Answer Engine Optimization reframes success. The metric is being included in the assistant's short answer or local module, not moving up a numeric position. Teams must replace the culture of ranking reports with an inclusion-first dashboard that tracks presence inside AI Overviews, local answer panels, and recommendation carousels. Inclusion is the new visibility because it corresponds to the moments where models can convert intent into an action the system controls.
6. Inclusion, Citations and Carousel Presence Are the New KPIs? Track Them Instead of CTR Alone

When outbound clicks decline, operators need different telemetry. Inclusion metrics — frequency in AI Overviews, citation counts inside assistant replies, and presence in recommendation carousels — reveal visibility that CTR misses. A dashboard built around these signals shows the difference between appearing in search results and appearing in the model's evidence set that drives purchases.
Measure inclusion, not just clicks
Traditional dashboards conflate impressions, clicks, and conversions. That conflation misleads when models synthesize answers directly in the interface. Instead, teams should instrument repeated prompt sampling across endpoints to capture whether products and pages are cited, which external sources the models prefer, and which carousel slots your brand occupies. These signals capture non-click visibility and expose when your product is being recommended without a click.
Similar web's findings that AI referral visits grew rapidly provide a precedent for tracking non-click referrals. Those referral measures are the operational evidence that inclusion matters even when CTR drops. At the same time, SEO vendors such as Ahrefs and Semrush documented the CTR shift after generative features rolled out, demonstrating that search volume alone no longer predicts traffic the same way. The combination of metrics suggests a concrete dashboard: citations per run, inclusion share in Overviews, carousel impressions where available, and a rolling sample of assistant replies for your top SKUs.
Use multi-model sampling to validate presence
To know whether you are consistently cited you must run repeat prompts across models and store the results. A practical experiment is a 10-run buyer prompt audit across multiple LLMs and AI-enabled search modes. Archive the outputs, extract cited sources, and compute recurrence rates. When the same external sources or pages appear repeatedly, those are the off-site channels that shape model behavior. When your pages appear repeatedly, you have evidence of model-level inclusion even if traditional analytics show lower click-through rates.
The complication worth naming is that sampling must be stable over time. Single-run checks show noise. Ten or more runs provide stable signals about recurring citations. Teams that act on single runs will misallocate effort; teams that operationalize repeated sampling will identify the channels that materially influence AI recommendations.
7. Off-Site Signals: PR, Reviews and Directories,Are the Training Data That Shape Live Recommendations
Off-site signals are not optional background SEO. They are training data and persistent evidence that feed model memory and live search inclusion. Models surface recurring external sources when answering buyer-intent prompts. That recurrence creates a leverage point: sustained presence in a small set of trusted off-site sources amplifies your brand's visibility inside generative answers.
Prioritize recurring sources, not one-off mentions
Operator audits show that models prefer corroborated evidence. A brand mentioned across a handful of authoritative directories, reviews, and trade articles will be surfaced more often than a brand with many one-off mentions. The practical strategy is to prioritize durable placements: directory inclusion with correct structured data, steady review acquisition in major review sites, trade PR in category outlets, and analyst or partner mentions that appear repeatedly. Those recurring signals influence both the pre-training memory of models and the live web signals the AI consults when it composes an answer.
Andy Crestodina's four-step off-site audit formalizes this approach into a practical method: generate buyer prompts, run multiple prompt samples across models, archive responses, and analyze which external sources repeat. The audit reveals the off-site channels that merit sustained investment rather than chasing every visible citation.
Run buyer-prompt audits this quarter
An operational experiment that teams can execute immediately is a 10-run buyer-prompt audit across multiple LLMs and Google AI Mode. Archive each run and extract the recurring external sources and brands. The output is a prioritized list of off-site channels to target for PR, directories, and review generation. The audit converts an abstract claim into a concrete action list: the channels you must own to appear in the models' shortlists.
The failure case here is doing PR as one-off stunts. Short-lived placements do not accumulate the recurrence models favor. Sustainable citation velocity is a cadence play: steady mentions, repeated listings, and recurring review acquisition create the signal the models learn to trust.
8. The Operational Reframe: Treat Product Data, Citation Strategy and Inclusion Metrics as Your New Channel
Do not think of AI as a new ranking algorithm. Think of it as a new channel that buys attention for the brands it already trusts. This reframing changes where teams allocate budget and who owns what inside the organisation. Product data engineering, feed cadence, and off-site citation velocity become first-class acquisition levers.
This quarter's single operational directive is concrete: run a product-data quality and feed-freshness audit, execute a 10-run buyer-prompt off-site source audit across multiple LLMs, and ship an 'AI inclusion' dashboard that tracks Overviews, citations and carousel impressions. Do these three things in sequence and you will move from passive rank-chasing to active inclusion work.
The organisational implication is also practical. Reorganise one team or one workflow to own machine-legible product signals and off-site citation velocity. That team should include a product-data engineer, a PR lead focused on recurring placements, and an analytics owner responsible for multi-model sampling and the inclusion dashboard. Make inclusion a quarter-one KPI and measure recurring citations monthly rather than waiting for CTR to recover.
Legacy organic ranking optimization will not preserve sales alone; brands that accept product data and citation inclusion as first-class channels will be the ones that maintain, and grow, revenue as AI-driven discovery matures.
By centering machine-legible truth and sustained citation velocity, you convert visibility into a repeatable channel rather than an unpredictable effect of a ranking algorithm.
Make Your Products Easier for AI to Recommend!
Var80 helps ecommerce brands structure product data, content, customer signals, and conversion workflows so products are not just ranked, but understood, trusted, and recommended across AI-led discovery journeys.
Make My Products AI-Ready
Leave a comment